在我们上篇文章讲的主从复制模式下,主节点一旦挂了,就需要人工进行主从切换,并且需要将新的主节点通知给客户端。这会大大影响系统的可用性,毕竟靠人工修复这个事情是很不靠谱的,先不说要耗费大量的时间;还有可能配置错误,导致出现问题。
哨兵机制就是通过自动化的手段来解决主节点挂了的问题~~
基本概念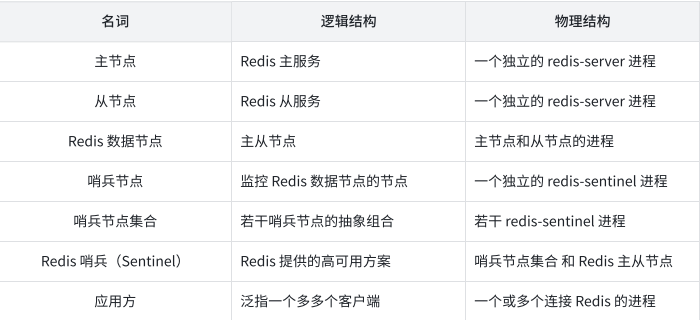
哨兵进程是通过独立的进程来体现的,和之前redis-server是不同的进程!!redis-sentinel不负责存储数据,只是对redis-server起到监控的效果。而且这里的哨兵节点,也会搞一个集合(多个哨兵节点构成的),这样能使系统拥有更高的可用性(毕竟只有一个哨兵节点的话,挂了咋办???)
人工恢复主节点故障
那么程序员如何恢复主节点呢?
首先,先看看主节点还能不能抢救,好不好抢救。
如果能快速抢救的话,就迅速抢救即可。如果短时间内无法抢救或者定位不到问题,就需要挑一个从节点设置为新的主节点。
1、把选中的从节点,通过slaveof no one,自立山头。
2、把其他的从节点,修改slaveof 的主节点ip port,连上新的主节点。
3、告知客户端(修改客户端配置),让客户端能够连接新的主节点,用来完成修改数据的操作。
当之前挂了的主节点,修好了之后,就可以作为一个新的从节点,再挂到这组机器中……
只要涉及人工干预,不说繁琐,至少很烦人~~另外,这个操作过程如果出错了咋办?可能导致的问题更加严重~~而且通过人工干预的做法,就算程序员第一时间看到了报警信息,第一时间处理~~恢复时间也需要半小时以上~~这半小时里,整个redis就一直不能写???
显然这种办法是不合适的。
哨兵自动恢复主节点故障
当主节点出现故障时,Redis Sentinel能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用。
架构图如下:
如果是从节点挂了,其实没有关系,但是如果是主节点挂了,哨兵就要发挥作用了:
1、一个哨兵节点发现主节点挂了(主观认同),还不够,需要多个哨兵节点来共同认同这件事情(客观认同),主要就是为了防止出现误判~~(可能是当前误判的这个哨兵到主节点的网络出现了波动)。
2、主节点确实是挂了,这些哨兵节点中就会推举出一个leader~~(哨兵节点最好是奇数个,这样就能少数服从多数,减少平票的情况)由这个leader负责从现有的从节点中挑选一个作为新的主节点。
3、挑选出新的主节点之后,哨兵节点就会自动控制该被选中的节点,执行slaveof no one 并且控制其他从节点,修改slaveof 到新的主节点上~~
4、哨兵节点会自动地通知客户端程序,告知新的主节点是谁,并且后续客户端再进行写操作,就会针对新的主节点进行操作了。
通过上面的介绍,我们可以看出哨兵具有以下核心功能:
1、监控
2、自动的故障转移
3、通知
这里的哨兵节点只有一个,可不可以呢?
有一个,也是可以的。但是如何哨兵节点只有一个,它自身是很容易出现问题的。万一这个哨兵节点挂了,后续redis节点也挂了,就无法进行自动恢复过程了。并且,只有一个哨兵节点出现误判的概率也是比较高的。毕竟网络传输数据是容易出现网络抖动或者延迟或者丢包的~~如果只有一个哨兵节点,出现上述问题之后,影响就比较大~~
基本的原则:在分布式系统中应该尽量避免使用单点。
使用docker部署哨兵-主从架构
当前要部署的docker架构图如下: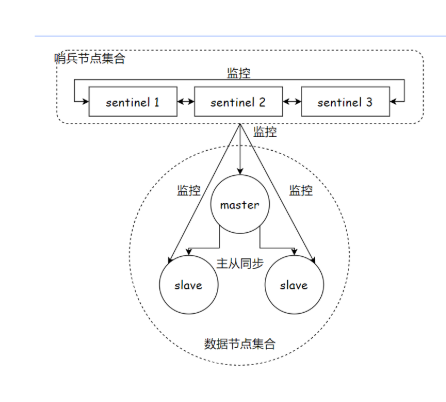
按理说这6个节点,是要在6个不同的服务器主机上的~~
我们学习阶段,只有一个云服务器,就在一个云服务器上来完成这里的环境搭建~~而在实际工作中,把上述节点放在一个服务器上,是没有任何意义的!!当前这么做只是迫于无奈~~
由于这些节点,还挺多的,相互之间容易打架,依赖的端口号/配置文件/数据文件……如果咱们直接部署,就需要小心翼翼地去避开这些冲突~~(类似于上文中主从配置的方式)
这么操作就会比较繁琐,也会和在不同主机上部署,存在较大差异~~使用docker就可以有效地解决上述问题。
docker科普:
不知道大家有没有听说过虚拟机(通过软件,在一个电脑上模拟出另外地一些硬件,相当于是构造了另一台虚拟地电脑),虚拟机这样的软件,就可以使用一个计算机,来模拟出多个电脑的情况~~但是虚拟机这个东西有一个很大的问题:比较吃配置。这个事情对于咱们的云服务器来说,亚历山大~~~
docker可以认为是一个“轻量级”的虚拟机~~起到了虚拟机这样的隔离环境的效果,但是又没有吃很多的硬件资源,即使是配置比较拉跨的云服务器,也是可以构造出好几个这样的虚拟的环境~~
docker也是现在后端开发比较流行的组件!!
docker中的关键概念
镜像和容器
这两者的关系就类似于“可执行程序”和“进程”的关系~~
比如,Edge浏览器就是一个可执行程序:
多次点击它就可以创建出多个进程:
而这里的镜像就相当于可执行程序,它可以自己创建也可以直接拿别人已经构建好的,一般是在dockerhub中获取,这个网站很像GitHub,包含了很多其他大佬们构建的镜像,当然,他也提供了redis官方构建好的镜像,可以直接拖下来使用。
而容器就像点击可执行程序后一个个的标签页,可以看作一个轻量级的虚拟机。

1、安装docker和docker-compose
安装docker:Docker安装教程详解-CSDN博客
安装完之后还需要对docker的镜像源进行修改:
在配置文件/etc/docker/deamon.json中加入:
1{ 2 "registry-mirrors": ["https://mirror.ccs.tencentyun.com"] 3}
配置完之后,重新启动docker:
1sudo systemctl daemon-reload 2sudo systemctl restart docker
docker-compose安装:
1# ubuntu 2apt install docker-compose 3# centos 4yum install docker-compose
2、停止之前的redis-server
service redis-server stop
这里如果之前有redis哨兵的话还需要停止redis哨兵
service redis-sentinel stop
3、使用docker获取redis镜像
docker pull redis:5.0.9
在git中我们使用pull从git仓库中拉取代码,dockerpull则是从docker从中央仓库中(默认是dockerhub拉取镜像)。
拉取到的镜像,里面包含一个精简的Linux操作系统,并且上面会安装redis。只要基于这个镜像创建一个容器跑起来,此时,一个redis服务器就搭建好了~~
完成这几步之后,我们就可以基于docker来搭建redis哨兵环境了。
我们可以使用docker-compose来进行容器编排,此处涉及到多个redis-server也有多个redis哨兵节点。每一个redis-server或者每一个哨兵节点就都作为一个单独的容器了。
docker中是通过一个配置文件,把具体要创建哪些容器,每个容器运行的各种参数,描述清楚。后续通过一个简单的命令,就能够批量地启动/停止这些容器了。
docker中式使用yml这样的格式来作为配置文件,和我们spring中的格式是一样的。
我们需要写两个配置文件:
1、创建三个容器,作为redis的数据节点(一个主,两个从)。
2、创建三个容器,作为redis的哨兵节点。
那能不能只写一个yml文件,直接启动这6个容器呢?
其实也是可以的,但是如果这6个容器同时启动,可能是哨兵先启动完成,数据节点后启动完成,此时哨兵就可能会先认为是数据节点挂了,虽然对于大局不影响,但是可能会影响到我们观察日志。
编排Redis主从节点
先创建一个redis文件夹,再创建出一个redis-data文件夹,然后在redis-data文件夹中创建docker-compose.yml,配置内容复制粘贴即可:
1version: '3.7' 2 3services: 4 master: 5 image: redis:5.0.9 6 container_name: redis-master 7 restart: always 8 command: redis-server --appendonly yes 9 ports: 10 - "6379:6379" 11 12 slave1: 13 image: redis:5.0.9 14 container_name: redis-slave1 15 restart: always 16 command: redis-server --appendonly yes --slaveof redis-master 6379 17 ports: 18 - "6380:6379" 19 depends_on: 20 - master 21 22 slave2: 23 image: redis:5.0.9 24 container_name: redis-slave2 25 restart: always 26 command: redis-server --appendonly yes --slaveof redis-master 6379 27 ports: 28 - "6381:6379" 29 depends_on: 30 - master
redis-docker配置内容解读: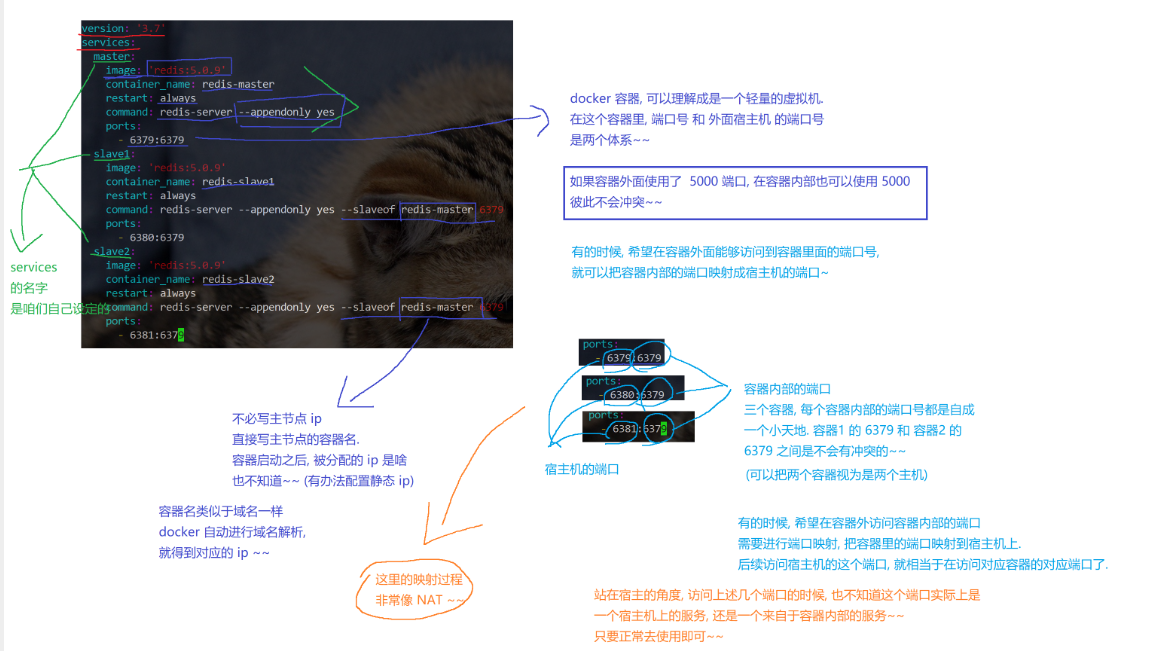
编写完之后,就可以启动当前的主从节点的容器了
docker-compose up -d
查看三个容器状态:

编排redis-sentinel节点
注意redis哨兵是单独的redis服务器进程,并且这些哨兵节点,会在运行的过程中对配置文件进行自动的修改。所以,就不能拿一个配置文件,给三个容器分别映射。
在redis文件夹中,再创建出一个redis-sentinel子文件夹,并写入docker-compose.yml。
1version: '3.7' 2 3services: 4 sentinel1: 5 image: "redis:5.0.9" 6 container_name: redis-sentinel-1 7 restart: always 8 command: redis-sentinel /etc/redis/sentinel.conf 9 volumes: 10 - ./sentinel1.conf:/etc/redis/sentinel.conf 11 ports: 12 - "26379:26379" 13 networks: 14 - redis-data 15 16 sentinel2: 17 image: "redis:5.0.9" 18 container_name: redis-sentinel-2 19 restart: always 20 command: redis-sentinel /etc/redis/sentinel.conf 21 volumes: 22 - ./sentinel2.conf:/etc/redis/sentinel.conf 23 ports: 24 - "26380:26379" 25 networks: 26 - redis-data 27 28 sentinel3: 29 image: "redis:5.0.9" 30 container_name: redis-sentinel-3 31 restart: always 32 command: redis-sentinel /etc/redis/sentinel.conf 33 volumes: 34 - ./sentinel3.conf:/etc/redis/sentinel.conf 35 ports: 36 - "26381:26379" 37 networks: 38 - redis-data 39 40networks: 41 redis-data: 42 external: 43 name: redis-data_default
哨兵-docker配置详解: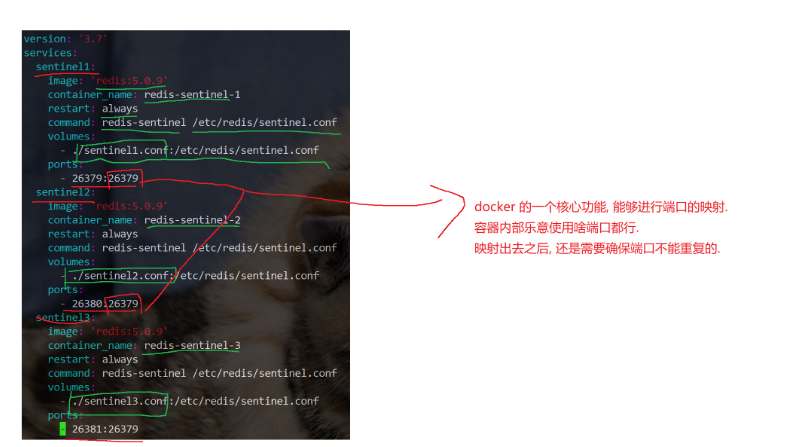
注意:
这里的网络如果不配置,那么这些哨兵集合是不知道要监控谁的,因为此时哨兵节点和redis节点处在不同的局域网中。
docker容器一次启动n个容器,这n个容器就会在同一局域网内。刚才我们是分别启动的,因此,redis-server节点在同一个局域网内,而三个哨兵是在另一个局域网内。默认情况下这两个网络是不互通的。
不配置启动哨兵的报错:
顺便解释下这里为什么使用redis-master而不是使用一个ip地址来标识这个主节点,这是因为每次重启docker容器,这个主节点的ip都可能使不同的。
这里的解决方案就是我们刚才的配置。
我们需要先列出当前docker中的局域网:
我们需要在docker-哨兵的配置项中修改这里的配置和redis主从节点所在的局域网相同,也就是这里的redis-data_default。
配置完之后,三个redis-server节点启动,就相当于自动创建了第一个局域网。再启动动后面三个哨兵节点,就直接让这三个节点加入到上面的局域网中,而不是创建新的局域网。
那如果把这六个容器,都写到同一个yml配置中,然后一次全部启动,不就能保证互通问题了吗??
如果使用这种方案,由于docker-compose启动容器的顺序不确定。不能保证redis-server一定是再哨兵之前启动的!!最终结果也能正确运行,但是执行的日志可能有变数。而分成两组启动,就可以保证上述顺序,观察到的日志是比较可靠的。



我们刚才也说了哨兵在工作的过程中,会不断修改配置文件的内容(注意:这里的配置是哨兵本身的配置,和上面docker的配置区分开!!!)。初始情况下,这三个配置文件的内容可以是一样的。
在当前目录下(redis-sentinel)创建sentinel1.conf文件。
vim sentinel1.conf
1bind 0.0.0.0 2port 26379 3sentinel monitor redis-master redis-master 6379 2 4sentinel down-after-milliseconds redis-master 1000
之后的内容复制即可:
cp sentinel1.conf sentinel2.conf
cp sentinel1.conf sentinel3.conf
哨兵配置文件内容解读:
配置完之后,我们可以打开哨兵的配置文件,可以看到在哨兵工作的过程中是会修改这里的配置文件的: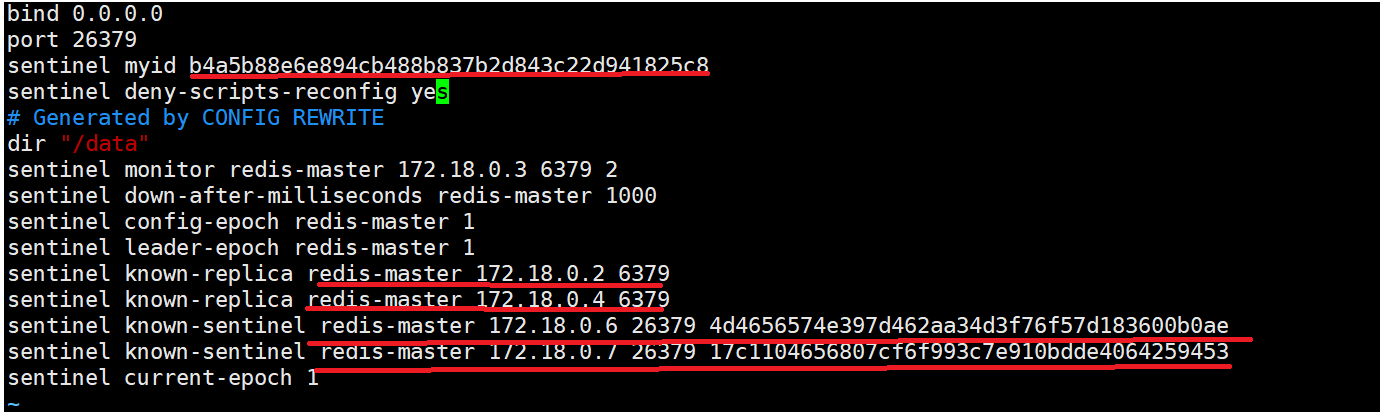
观察哨兵工作过程(面试题!!!)
哨兵存在的意义是能够在redis主从结构出现问题的时候(比如主节点挂了),此时哨兵节点就能够自动地帮我们重新选举出一个主节点,来代替之前地节点,保证整个redis的可用性。
下面,我们手动把主节点干掉:
docker stop redis-master
使用命令,查看日志:
docker-compose logs
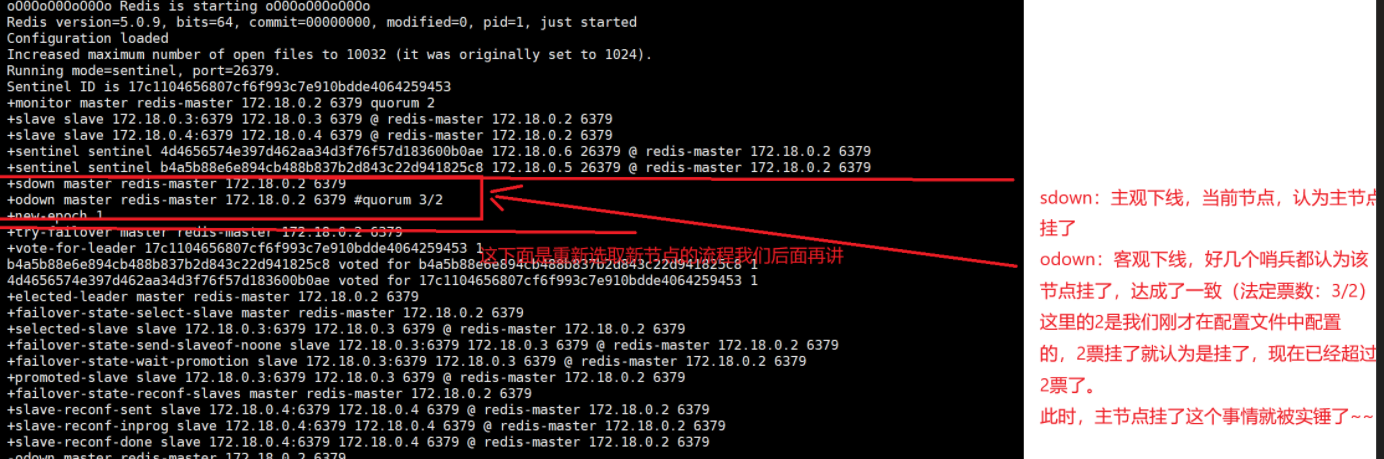
哨兵重新选取主节点的流程
1、主观下线
哨兵节点通过心跳包,判定redis服务器是否正常工作。如果心跳包没有如约而至,就说明redis服务器挂了。此时还不能排除网络波动的影响,因此就只能单方面认为这个redis节点挂了。
2、客观下线
多个哨兵都认为这个主节点挂了(认为挂了的哨兵节点达到法定票数),哨兵们就认为这个主节点是客观下线。
那有没有可能多个哨兵节点出现误判呢?
有的,比如出现严重的网络波动,导致所有的哨兵都联系不上redis主节点误判成挂了。
如果出现这个情况,怕是客户端也连不上这个redis主节点了,此时这个主节点基本也就无法正常工作了。“挂了”不一定是进程崩了,只要无法正常访问就可以视为是挂了……
3、要让多个哨兵选出一个leader节点,由这个leader负责选出一个从节点作为新的主节点。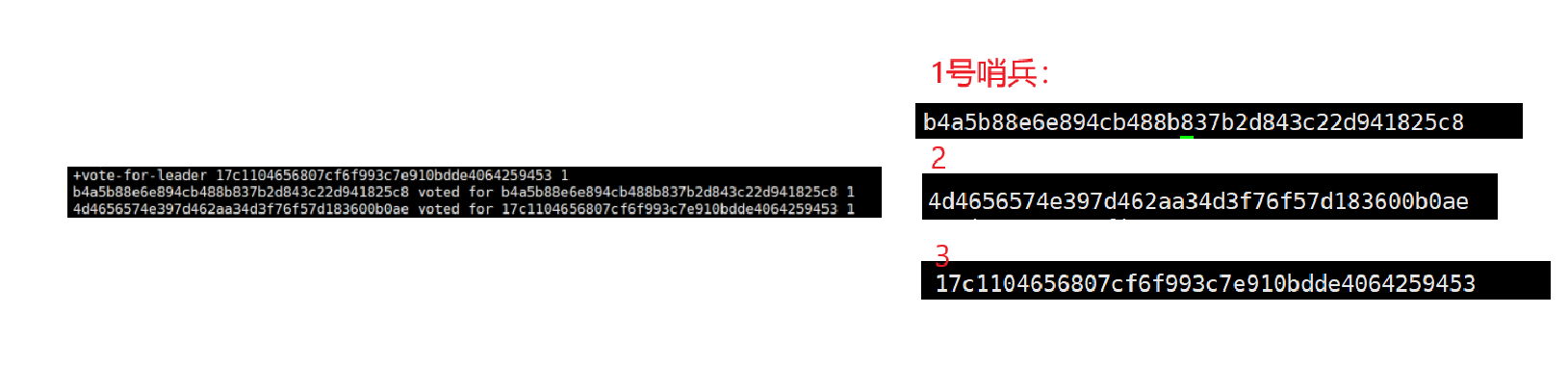
观察刚才的日志,结合哨兵配置中的sentinel myid,也就是说3号哨兵发现主节点挂了之后,立刻给自己投了一票(推举自己成为leader)。紧接着,2号哨兵和1号哨兵都投给了3号哨兵,此时,三号哨兵就成为了leader。
如果总的票数超过哨兵总数的一半,选举就完成了。把哨兵个数设置为奇数个,就是为了方便投票。
上面的投票过程,主要还是看哪个哨兵反应快,网络延时小
4、此时leader选举完毕,leader就要挑选出一个从节点,作为新的主节点。
如何选取新的主节点呢?
1、优先级:每个redis数据节点都会在配置文件中,有一个优先级的设置。slave-pripority,优先级高的从节点就会胜出~~
2、offset最大:offset就是我们在主从复制中讲道德从节点从主节点这边同步数据的进度,数值越大,说明从节点的数据和主节点就越接近。
3、run id :每个redis节点启动的时候随机生成的一串数字(大小全凭运气了)
把新节点指定好了之后leader就会控制这个节点,执行slave no one,成为master,再控制其他节点,执行slaveof,让这些节点,以新的master作为主节点了。
这里我们实验的过程中是以宿主机端口6380的从节点变为主节点: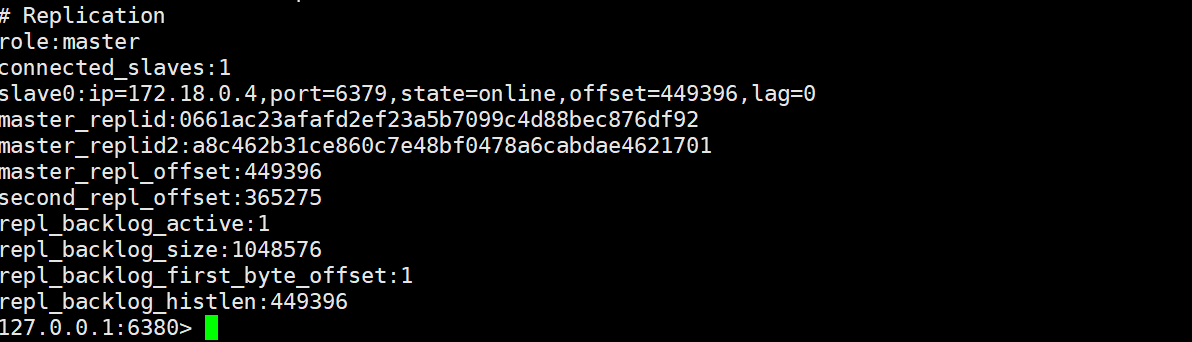
此时,我们讲刚才挂掉的主节点6379重启:
docker start redis-master

可以看到我们此时的主节点变为从节点了: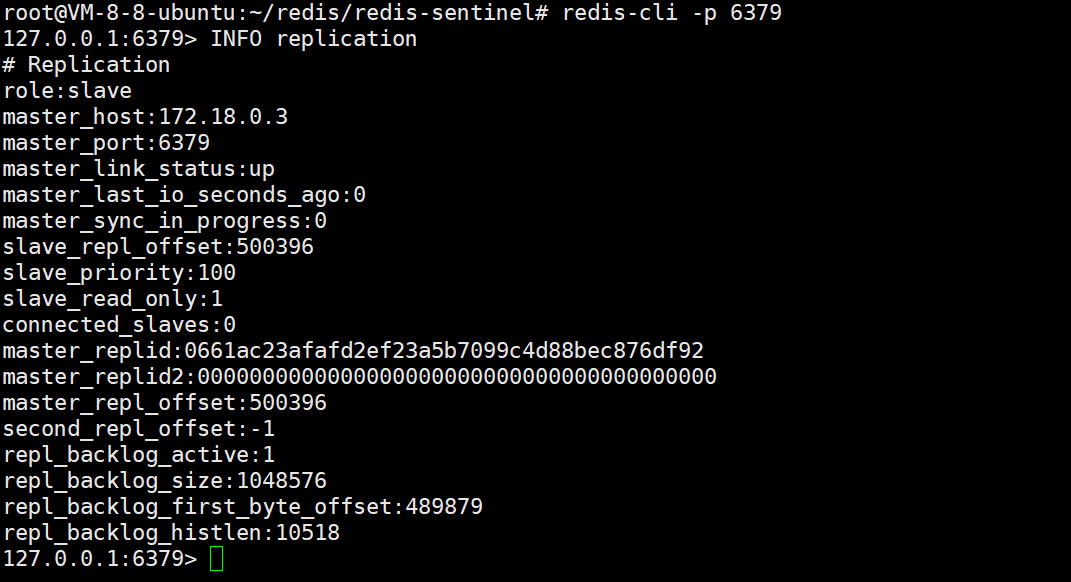
总结
redis哨兵能够解决主节点宕机之后需要人工干预的问题,提高了系统的稳定性和可用性~~
注意事项:
- 哨兵节点不能只有一个,否则哨兵节点挂了也会影响系统的可用性。
- 哨兵节点最好是奇数个,方便选举leader,得票更容易超过半数。大部分情况三个就够用了,哨兵节点可以使用一些配置不高的机器来部署。(但是不能搞一个机器部署三个哨兵,这就和掩耳盗铃没啥区别了~~~)
- 哨兵节点不负责存储数据,仍然是redis主从节点负责存储。
- 哨兵+主从复制解决的问题是“提高可用性”,不能解决“极端情况下写丢失”的问题(写入数据的时候网络出现波动,导致写入数据丢失)
- 哨兵+主从复制不能提高数据的存储容量,当我们需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了。(这个可以用redis集群解决,redis集群就是解决存储容量问题的有效方案)。
《Redis_16_哨兵》 是转载文章,点击查看原文。



